040103 Extract Data
2023-04-10
위 벳지는 수강을 완료하고 받은 뱃지입니다.
Get Data into the EMS

01 Set up a Data Pipeline
Extract Data

1 소개
11 학습 목표
환영! 이 과정을 완료하면 다음을 수행할 수 있습니다.
- Data Jobs 및 Replication Cockpit으로 추출 설정
- 추출을 위해 데이터 작업 또는 Replication Cockpit을 사용할 시기 구분
- 매개변수로 작업 가속화
- 전체 및 델타 추출 모두 사용
이 과정의 실습 섹션을 따라갈 수 있도록 먼저 “시스템에 연결” 과정을 완료하는 것이 좋습니다.
2 추출 접근법
21 추출 도구
21 올바른 도구 선택
연결을 설정하면 다음으로 추출이 진행됩니다. 다음 도구 중 하나 이상을 사용하여 추출을 구성할 수 있습니다.
- 데이터 작업
- 복제 조종석
다음 두 가지 질문을 통해 사용할 도구를 결정할 수 있습니다.
- 프로세스 커넥터/추출기는 실시간입니까?
- 운영 사용 사례(일상 작업) 에 필요한 데이터입니까 ?
각 도구의 사용 사례를 살펴보겠습니다.
22 데이터 작업
데이터 작업은 일정 기반 이며 델타 및 전체 추출을 모두 처리할 수 있습니다 . 연결이 실시간인 경우 실시간 추출이 필요하지 않은 더 많은 정적 테이블(예: 메타데이터/마스터 데이터 테이블)에 대해 데이터 작업 추출을 계속 사용할 수 있습니다. 데이터 작업은 분석 데이터 모델을 위한 정기적인 데이터 추출에 가장 적합합니다 . 즉, 항상 최신 데이터를 확보하기 위해 서두르지 않는다면 데이터 작업으로 충분합니다.

전체 추출과 델타 추출의 차이점이 무엇인지 궁금하십니까?
전체 추출은 전체 소스 시스템 테이블을 Celonis로 로드 하는 경우입니다 . 소스 시스템 테이블의 새로운 스냅샷을 그리고 이전에 추출한 데이터를 완전히 덮어씁니다.
델타 추출은 소스 시스템에서 새 데이터 또는 업데이트된 데이터의 부분 로드를 수행하는 경우입니다 . 데이터 작업을 사용한 델타 추출은 변경 로그가 아닌 필터 에 의존합니다.
전체 추출은 기본적으로 크기가 더 크며 델타 추출보다 시간이 오래 걸립니다.

23 복제 조종석
Replication Cockpit을 사용하면 실시간 연결을 위해 전체 및 델타 추출을 수행할 수 있습니다. 운영 사용 사례 (예: 사용자가 비즈니스 앱과 같이 데이터에 대해 작업하는 경우) 에 사용되는 모든 테이블의 경우 Replication Cockpit을 사용하여 추출하는 것이 좋습니다. Replication Cockpit을 사용한 델타 추출은 변경 로그를 사용합니다 . 데이터 풀에 실시간 연결을 추가하면 UI에 즉시 나타납니다.

Replication Cockpit은 ServiceNow 및 Oracle DB, HANA DB, MSSQL DB와 같은 데이터베이스와 함께 주로 SAP 시스템에 서비스를 제공합니다.
Salesforce를 사용한 실시간 추출은 Streaming Cockpit 이라는 별도의 도구를 사용합니다 . 이것은 이 과정의 범위를 벗어나지만 관심이 있는 경우 이 도움말 문서 와 이 마이크로 러닝 을 살펴보십시오 .
24 주요 차이점
다음은 Data Job과 Replication Cockpit 추출을 시각적으로 요약한 것입니다.

실시간이란 무엇입니까?
커넥터 또는 추출기를 참조할 때 실시간은 단순히 새 데이터 또는 업데이트된 데이터가 EMS로 푸시되는 속도가 훨씬 빠르며 변경 로그를 기반으로 하거나 간단히 말하면 소스 시스템의 데이터 변경 사항을 의미합니다 .
데이터 작업은 수동으로 설정한 주기적인 일정에 따라 실행되는 반면 , 실시간 방법은 소스 시스템의 변경 로그를 지속적으로 확인하고 변경 사항이 감지되면 새 추출을 트리거합니다 .
실시간 커넥터 식별
Marketplace에서 커넥터를 선택하면 어떤 커넥터가 실시간인지 확인할 수 있습니다.

Replication Cockpit에 대한 실시간 연결 설정에 대한 빠른 검토가 필요한 경우 “시스템에 연결” 과정에서 이 페이지를 살펴보십시오.
다음 단원에서는 각 도구를 사용하여 추출을 살펴보고 가능한 경우 연습해 보겠습니다. 먼저 데이터 작업!
3 데이터 작업 - 데이터 추출
31 적절한 데이터 추출
311 필요한 것을 추출하십시오
데이터를 추출할 때 사용하는 시스템이 무엇이든 관계없이 먼저 비즈니스 프로세스를 이해하여 필요한 테이블을 정확히 파악하는 것이 좋습니다.
전체 데이터베이스를 추출하여 삶을 단순하게 만드는 것은 어떨까요?
간단한 이유로 전체 데이터베이스 추출은 다음과 같습니다.
- 너무 오래 걸리다,
- 소스 시스템에 부담을 주거나
- 불필요한 클라우드 스토리지를 차지하고
- 비싸다!
범위를 좁히기 위해 묻는 질문
대부분의 경우 프로세스 커넥터로 작업하는 경우 추출 템플릿 으로 작업하게 됩니다 . 즉, 새 추출을 만들 때 기존 추출을 조정하거나 작업을 간소화하려면 다음과 같은 몇 가지 질문을 스스로에게 던져야 합니다.
- 어떤
프로세스 단계가 필요하며 이러한각 단계의 타임스탬프는 어디에 있습니까? - 프로세스에서 케이스를 나타내는 것은 무엇 이며
각 케이스의 ID는 무엇입니까? - 프로세스를 분석하는 데 필요한 추가 차원/필터는 무엇 입니까?
이러한 질문은 프로세스와 관련된 소스 시스템 테이블 및 열을 결정하는 데 도움이 됩니다. 다음으로 추출하는 동안 특정 필터가 적용 되는지 확인하여 추출되는 데이터의 양을 줄이고 성능을 향상시킬 수 있습니다 . 예를 들어 필터는 날짜 및 시간 제한, 문서 유형 또는 언어 키일 수 있습니다.
마찬가지로 올바른 데이터만 추출하도록 하거나 나중에 변환에서 중복 조인을 방지하기 위해 추출 시 테이블을 조인 해야 할 수 있습니다 .
요컨대 올바른 데이터가 필요하며 이는 추출에서 올바른 테이블, 필터 및 조인을 식별하는 것을 의미합니다 .
312 샘플 프로세스 및 해당 테이블
이 과정의 샘플 데이터 작업 추출을 위해 SAP 구매-지불(P2P) 테이블을 사용합니다.
P2P(Purchase-to-Pay)는 조달(구매)과 미지급금(지불)을 결합합니다. 벤더 구매 주문을 관리하고 처리하는 프로세스를 말합니다.
다음은 구매-지불 프로세스의 단순화된 “예시” 버전입니다.

이제 이 프로세스에 대한 관련 SAP 테이블을 살펴보겠습니다. 각 테이블에는 필요한 정보의 일부가 포함되어 있으며 프로세스를 매핑하려면 모든 정보를 추출해야 합니다.
이 경우 SAP에서 오는 세 가지 일반 범주의 테이블이 있습니다.
- 핵심 테이블
- 변경 테이블
- 이름 매핑 테이블.
인상을 얻을 수 있도록 개별적으로 살펴보겠습니다.
313 P2P 핵심 프로세스 테이블
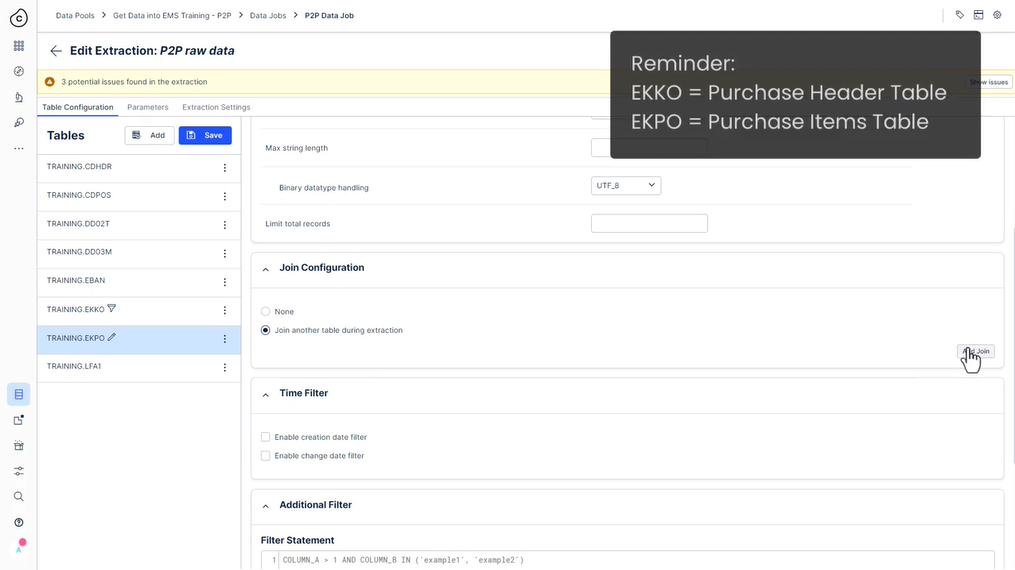
핵심 프로세스 테이블은 케이스 및 케이스 ID , 케이스와 관련된 마스터 데이터 , 타임스탬프 , 특히 생성 이벤트와 같은 프로세스에 대한 필수 정보를 찾을 수 있는 곳입니다 . P2P 프로세스에는 EBAN, EKKO, EKPO 및 LFA1이 있습니다 . 이것들은 당신에게 아무 의미가 없을 가능성이 높은 기술 이름이므로 여기에 각 테이블에 대한 간략한 설명이 있습니다.
이것은 가져가야 할 것이 많으므로 자유롭게 빠르게 탐색하고 필요한 경우 나중에 다시 방문하십시오.
EBAN - 구매 요청 품목
EBAN은 자재 및 수량을 포함한 구매 요청 항목에 대한 정보를 포함합니다. 기본 키는 클라이언트, 구매 요청 번호 및 구매 요청 항목 번호 열의 조합입니다. BADAT는 요청 타임스탬프에 사용되는 필드입니다.

EKPO - 구매 문서 항목
EKPO 는 EBAN과 유사하지만 구매 주문 항목을 추적합니다 . 이 테이블의 각 행은 주문 수량, 정가, 공장 및 자재 번호를 추적합니다. 여기에서 기본 키도 여러 열로 구성됩니다.

EKKO - 구매 주문 헤더
여러 구매 주문서 항목이 하나의 구매 주문서 로 묶입니다 . 구매 주문 정보는 EKKO 에 저장됩니다 . 이 테이블은 공급업체, 구매 문서 유형 및 통화에 대한 정보를 저장합니다. AEDAT 는 구매 주문 생성 타임스탬프에 대한 필드입니다.
간단히 말해서 하나의 구매 주문서에는 하나 이상의 구매 주문서 항목이 포함되어 있으므로 EKKO(구매 주문서)는 EKPO(구매 주문서 항목)와 1:다 관계입니다.

LFA1 - 벤더 마스터
마지막으로 LFA1은 공급업체용 테이블입니다. 각 행에는 이름, 번호, 국가와 같은 공급업체에 대한 기본 정보가 포함되어 있습니다.

314 P2P 변경 테이블
이제 변경 테이블(CDHDR 및 CDPOS)을 살펴보겠습니다.
이러한 테이블은 많은 SAP 테이블에서 변경 사항을 캡처합니다. 변경을 수행한 사용자, 시간, 변경된 필드 및 변경된 값을 포함하여 다른 테이블에서 수행된 모든 변경에 대한 정보를 저장합니다. 상상할 수 있듯이 이 표에서 “변경” 프로세스 단계에 대한 많은 정보를 찾을 수 있습니다.
CDHDR - 문서 헤더 변경
CDHDR은 헤더 또는 상위 테이블이며 작성된 각 변경 트랜잭션에 대해 하나의 행을 포함합니다. 한 번에 여러 변경 사항을 실행하고 저장하는 경우(예: 여러 테이블 열을 변경하는 경우) CDHDR은 이 트랜잭션을 한 행에 저장합니다.
여기에서 해당 변경 번호, 변경을 트리거한 사람의 사용자 이름, 변경 실행에 사용된 SAP의 트랜잭션 코드를 찾을 수 있습니다.
또한 변경 날짜와 변경 시간을 찾습니다. 이러한 타임스탬프는 프로세스 흐름의 변경 사항을 올바른 연대순으로 포함하는 데 매우 중요합니다.

CDPOS - 문서 항목 변경
CDPOS 테이블에는 변경 트랜잭션 내에서 변경된 각 열에 대해 하나의 행이 포함됩니다.
따라서 이전 예제와 같이 한 번에 여러 필드를 변경하면 변경된 각 필드에 대해 하나의 행을 찾을 수 있습니다. 그렇기 때문에 이 테이블에는 변경 번호 외에도 변경된 테이블과 영향을 받은 열이 표시됩니다.
또한 “CDPOS”에는 해당 테이블에서 변경된 행이 포함됩니다. 이는 “TABKEY” 필드로 표시됩니다. 따라서 “TABKEY”는 항상 변경된 테이블에서 변경된 행의 기본 키를 참조합니다.
마지막으로, 무엇보다도 설정된 이전 값과 새 값도 찾을 수 있습니다.

요약하면 이 두 테이블은 모든 변경 사항이 여기에 저장되기 때문에 프로세스 흐름을 분석하는 데 매우 중요합니다.
알다시피 CDHDR 및 CDPOS 테이블은 EKPO 및 EKKO 테이블과 매우 유사한 관계를 가집니다. 항상 헤더 테이블 (우리의 경우 CDHDR 및 EKKO)과 항목 테이블 (EKPO 및 CDPOS의 경우)이 있습니다 . 헤더 테이블의 한 항목은 항목 테이블의 하나 또는 여러 항목에 항상 연결될 수 있습니다.
이와 같은 헤더-항목-관계는 다양한 소스 시스템에서 관찰할 수 있으며 일반적으로 어떻게 작동하는지 이해하면 많은 도움이 됩니다.
315 P2P 이름 테이블
이미 Celonis에서 Analyzes로 작업한 적이 있다면 자체 설명이 가능한 이름으로만 작업했을 가능성이 큽니다.
그렇다면 데이터 통합의 시스템 데이터베이스에 있는 기술 이름에서 분석의 보다 사용자에게 친숙한 이름으로 이동하는 방법은 무엇입니까? SAP P2P의 경우 이름 테이블 DD02T 및 DD03M이 사용됩니다. “테이블 텍스트 정보”를 저장하고 나중에 “이름 매핑”을 수행하는 데 도움이 됩니다. 이 두 테이블에는 SAP 테이블과 열에 대한 정확한 번역이 포함되어 있습니다.
DD02T - 테이블 이름 매핑
테이블 DD02T에는 다른 언어로 된 기술 테이블 이름에 대한 번역이 포함되어 있습니다.

DD03M - 열 이름 매핑
테이블 DD03M에는 테이블 열의 변환이 포함되어 있습니다.

요약하면 이 두 테이블을 사용하여 분석가가 기술 테이블 및 열 이름에 익숙하지 않을 수 있으므로 자명한 이름을 표시할 수 있습니다.
316 테이블 확인
이전에 SAP Purchase-to-Pay 테이블로 작업한 적이 없다면 테이블 약어와 열 이름을 이해하고 기억하기 어려울 수 있습니다.
이전 페이지에서 본 것처럼 테이블에는 “EKPO” 테이블의 구매 주문 번호에 대한 “EBELN” 또는 클라이언트에 대한 “MANDT”와 같은 열 이름이 포함되어 있습니다.
필요할 때 기술 필드 이름을 조회할 수 있는 것이 중요합니다. 나중에 변환을 만들 때 참조할 이름이기 때문입니다. SAP 테이블에 대한 자세한 정보와 번역을 얻을 수 있는 아주 좋은 도구 중 하나는 “ LeanX “ 웹사이트입니다 .
예를 들어 테이블 “ EKKO “ 를 보면 . 이전에 처리했던 구매 주문에 대한 테이블입니다. 테이블을 클릭하면 기술 이름의 각 번역과 함께 테이블의 모든 열에 대한 전체 개요와 설명을 볼 수 있습니다.

“구매 문서 범주”와 같은 일부 열의 경우 필드의 가능한 값을 볼 수 있습니다.
가능한 값을 클릭하면 견적 요청, 구매 주문서, 계약 또는 일정 계약과 같은 다른 종류의 개체를 나타내는 다른 문자가 있음을 알 수 있습니다.

테이블 이름이 아닌 추출에 집중
나중에 작업할 때 이 참조를 염두에 두십시오. 이 과정에서는 SAP 필드와 테이블을 암기하는 것이 아니라 추출의 필수 요소에 집중하기를 바랍니다.
32 새 추출 설정
321 Vertica SQL 사용
Celonis 추출 작업을 시작하기 전에 Celonis 데이터 통합에서 Vertica SQL을 사용한다는 점에 유의하십시오 .
추출의 경우 다음에 대해 잘 알고 있어야 합니다.
- SQL 테이블 조인,
- “WHERE” 절,
- 및 데이터 유형.

검토가 필요하십니까? Vertica 참조 매뉴얼 을 확인 하고 필요한 것을 검색하십시오.
이 리소스는 탐색하기가 약간 어렵다는 것을 알고 있습니다. 또는 이와 같은 PostgreSQL 리소스를 참조할 수도 있습니다 . PostgreSQL은 차이가 거의 없이 Vertica SQL과 가장 가까운 구문을 가지고 있습니다.
걱정하지 마세요. 물론 이 과정을 계속 진행하면서 간단히 배울 수 있습니다.
322 새 추출 설정
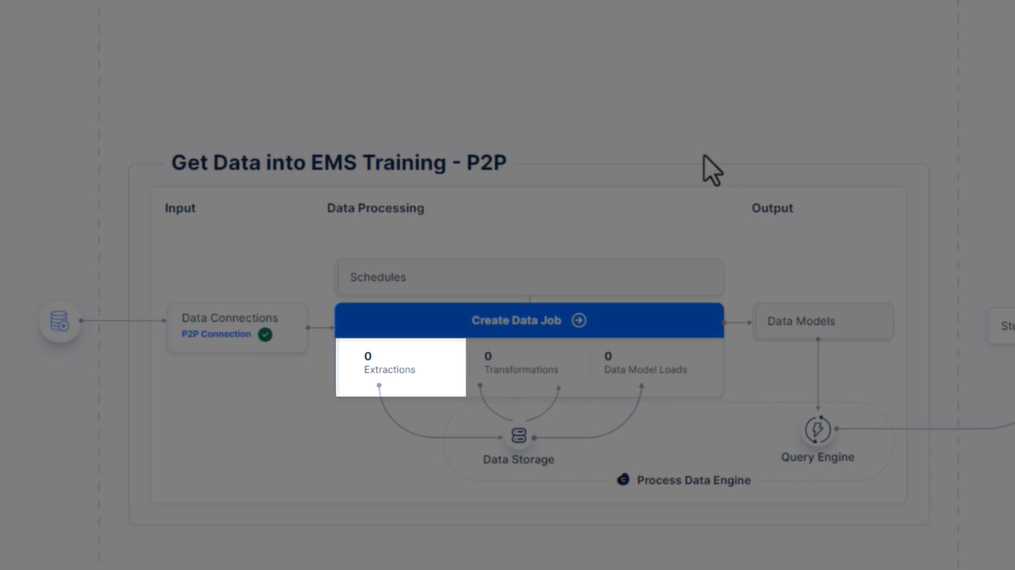
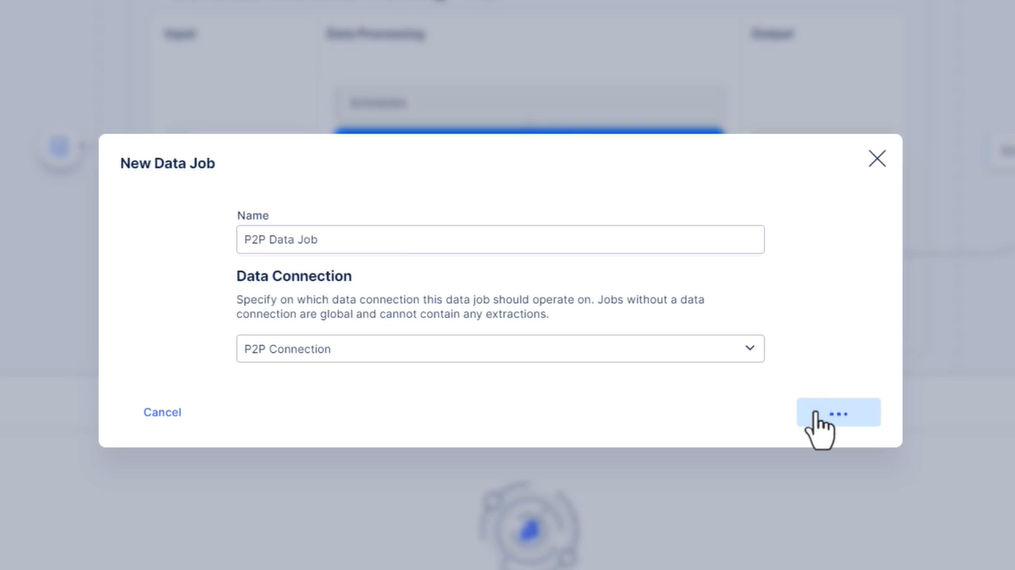
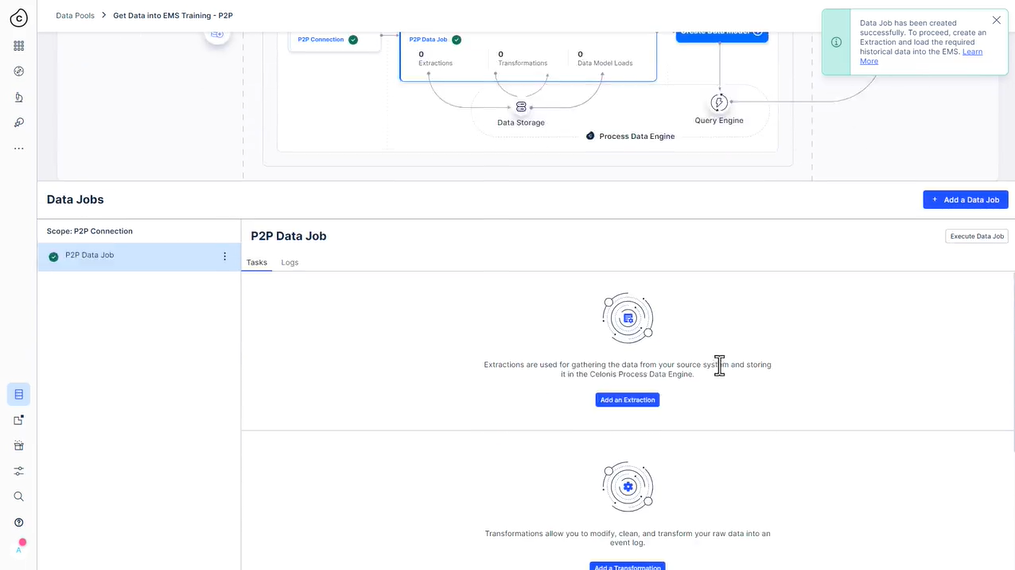
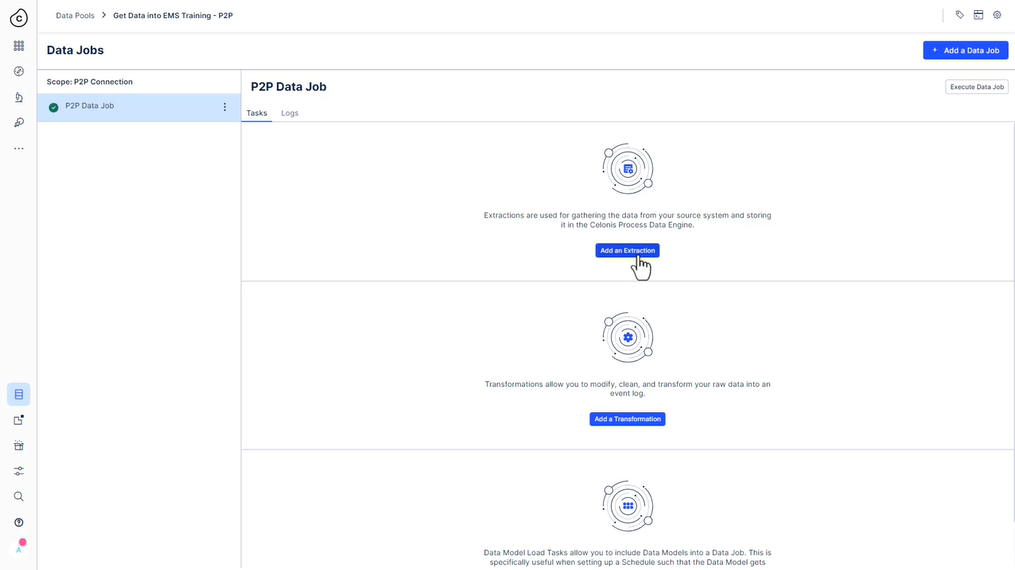
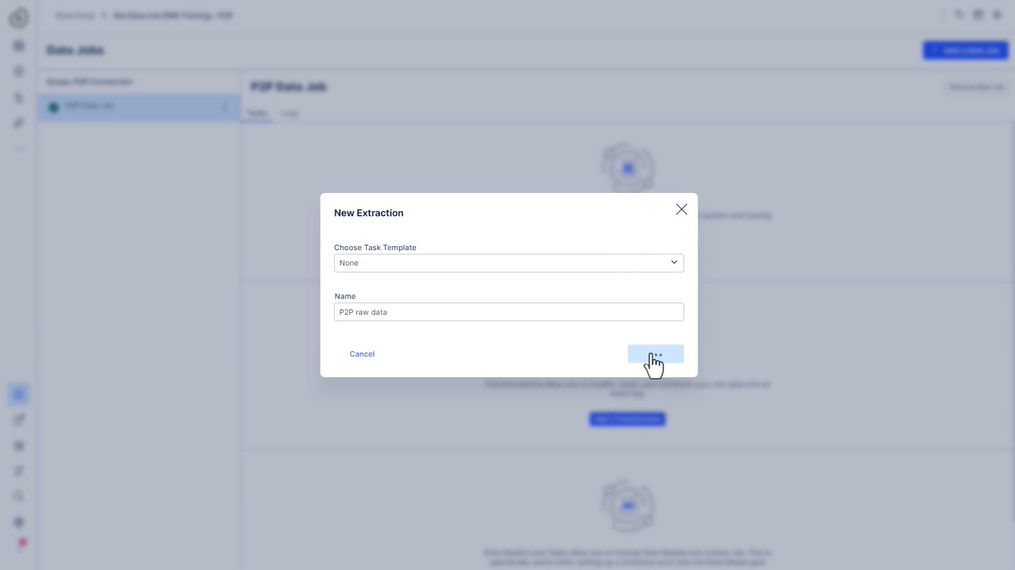
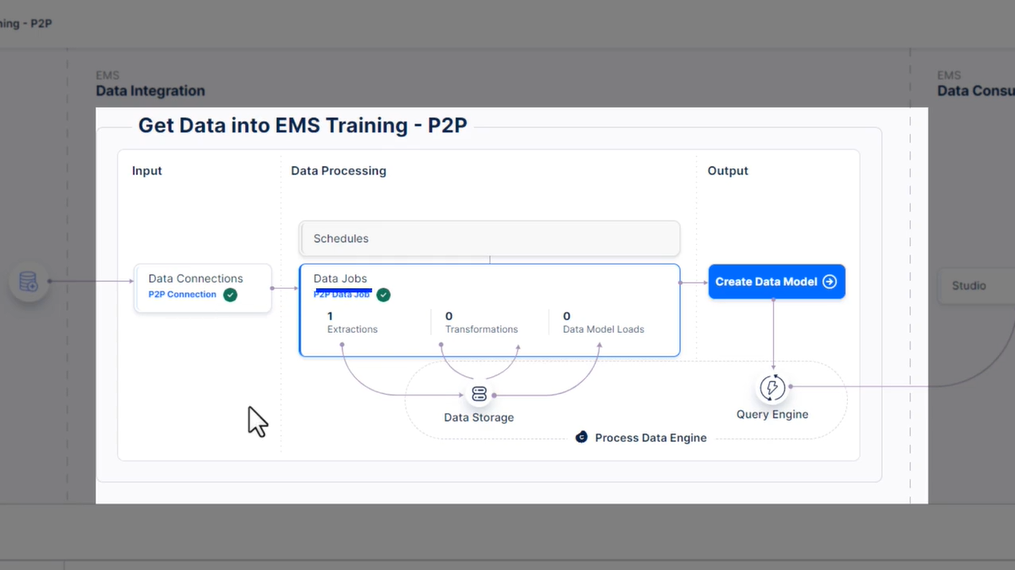
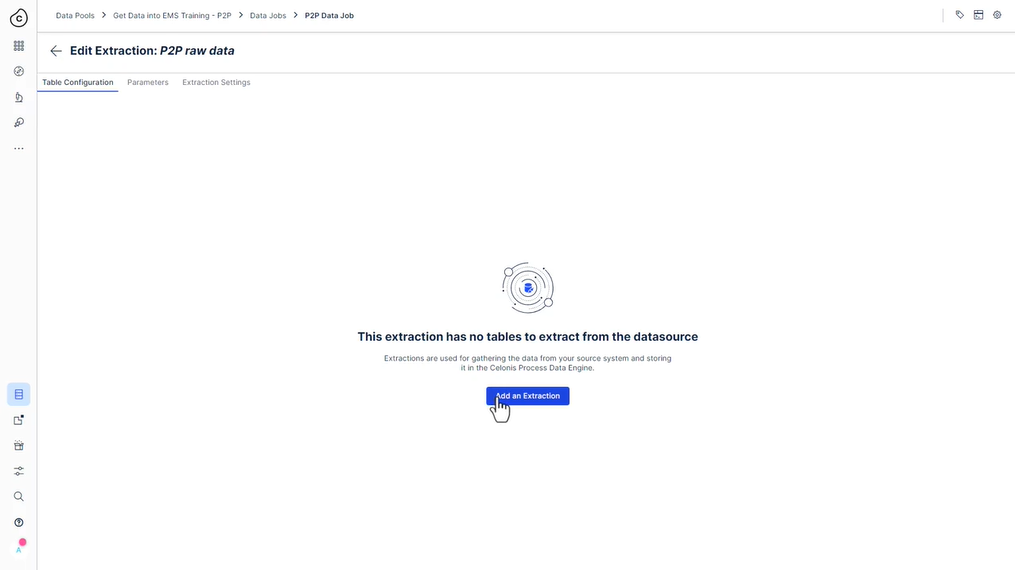
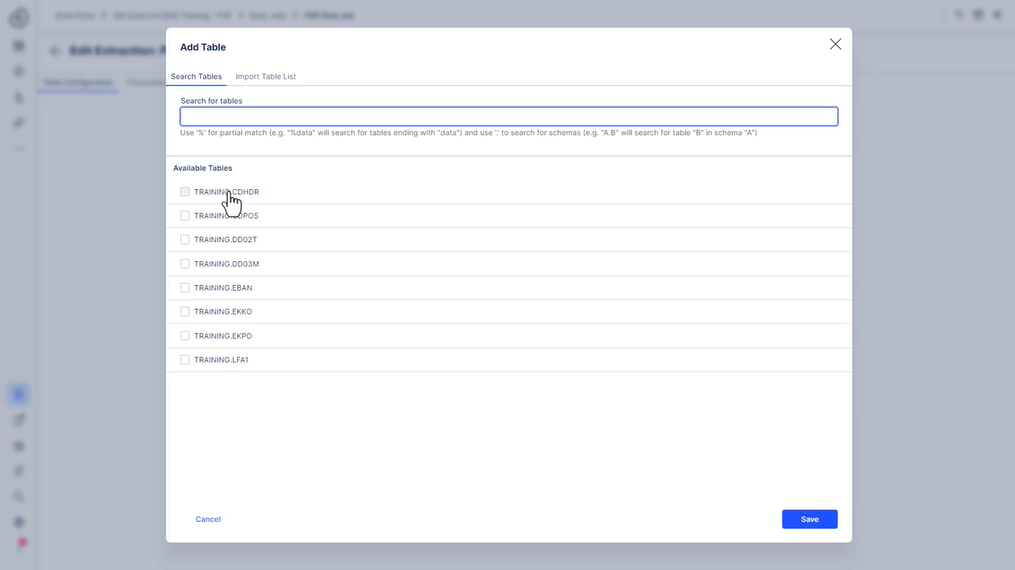
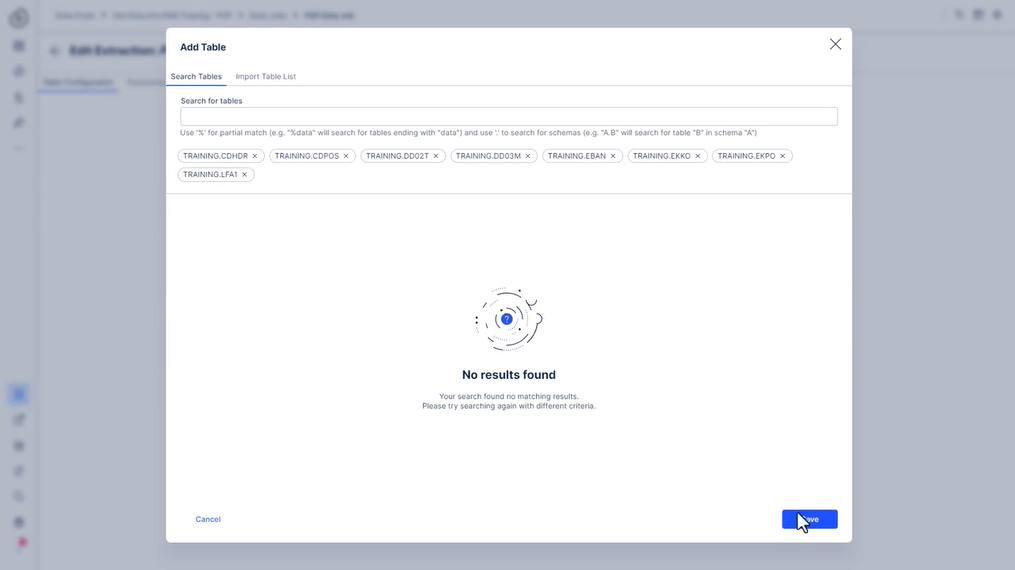
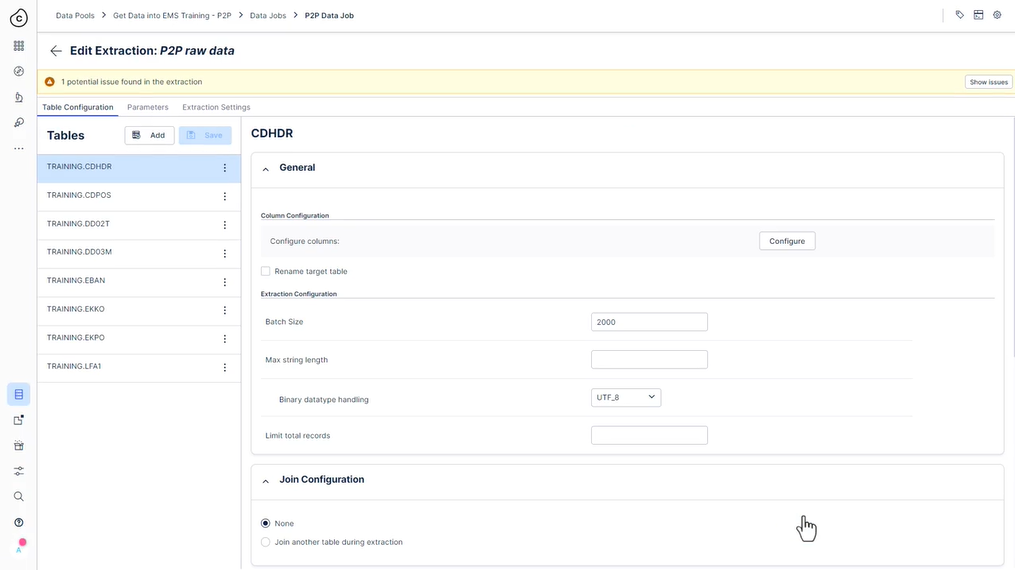
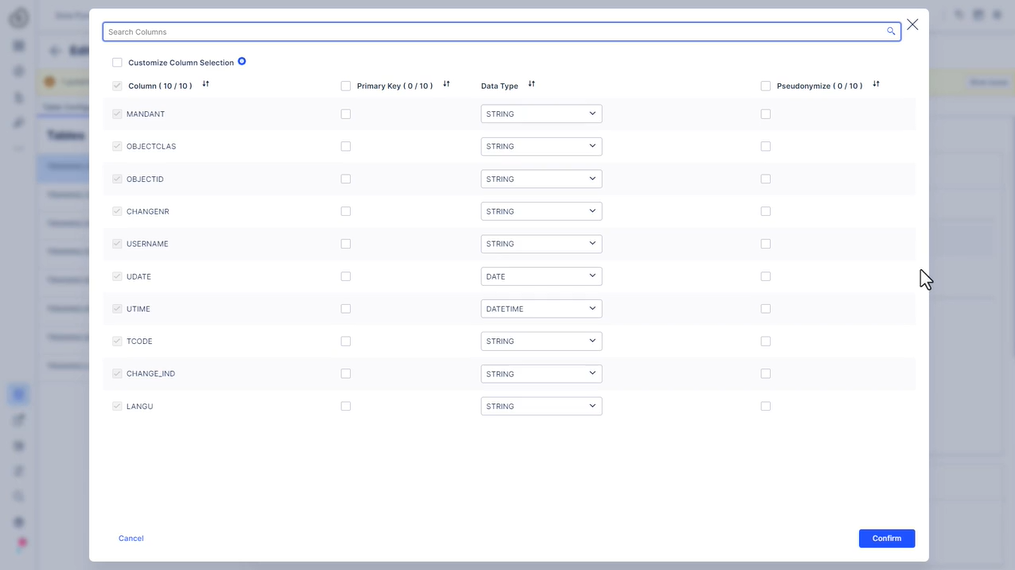
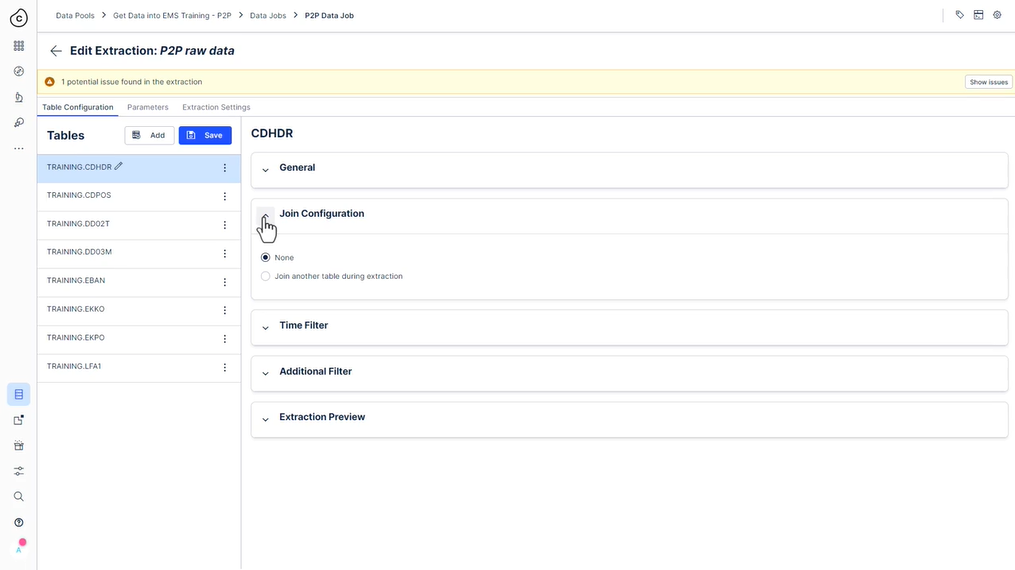
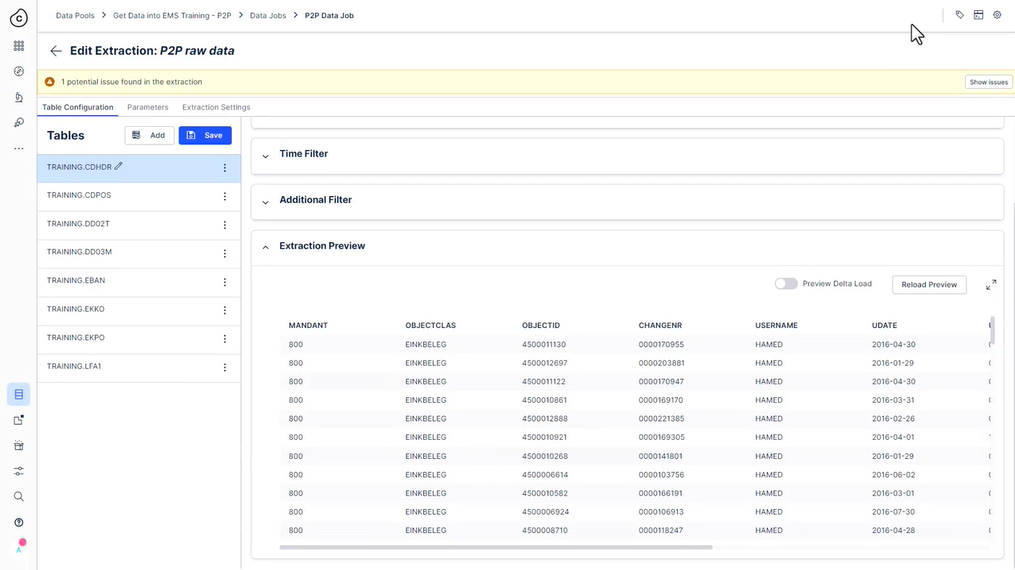
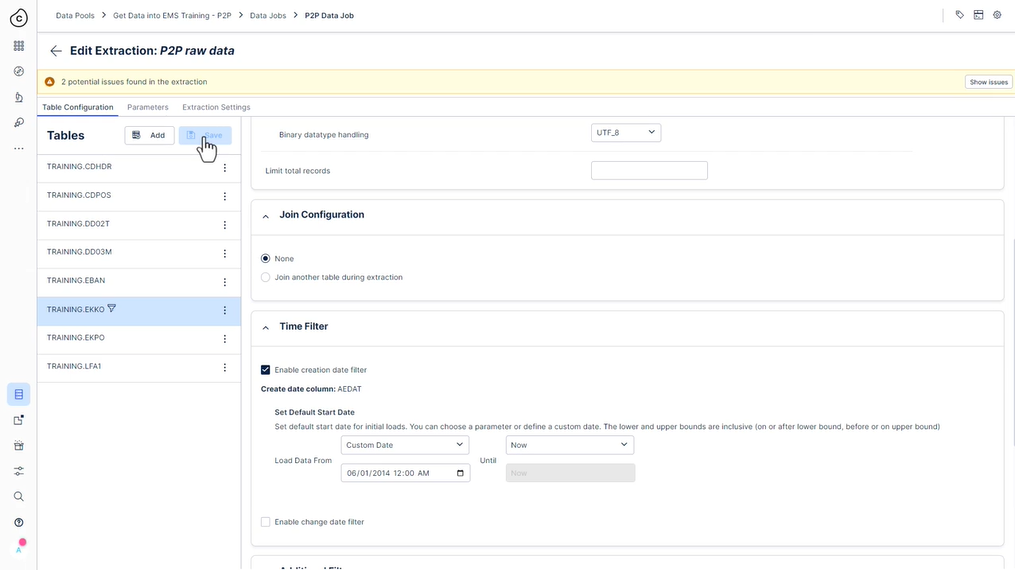
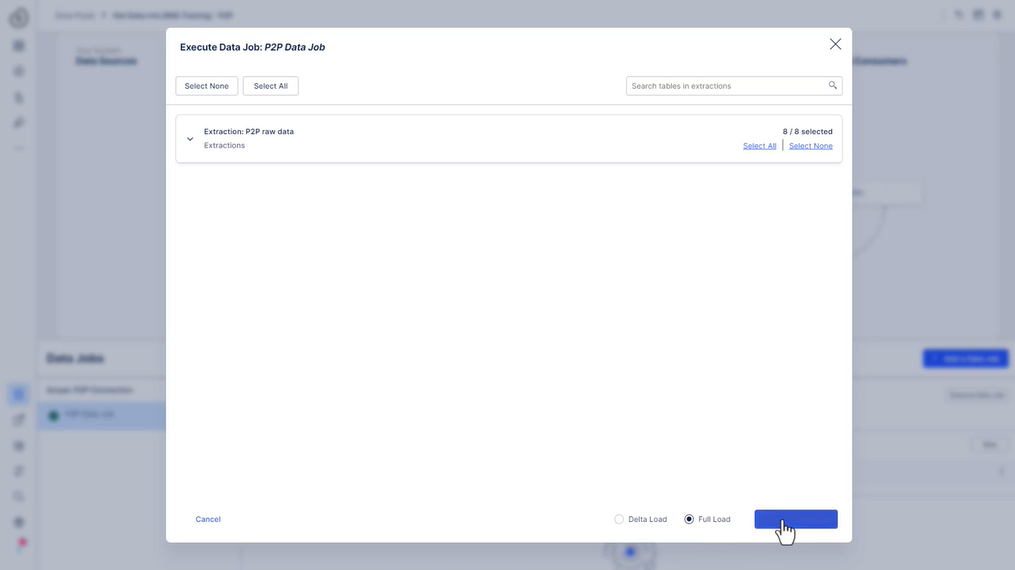
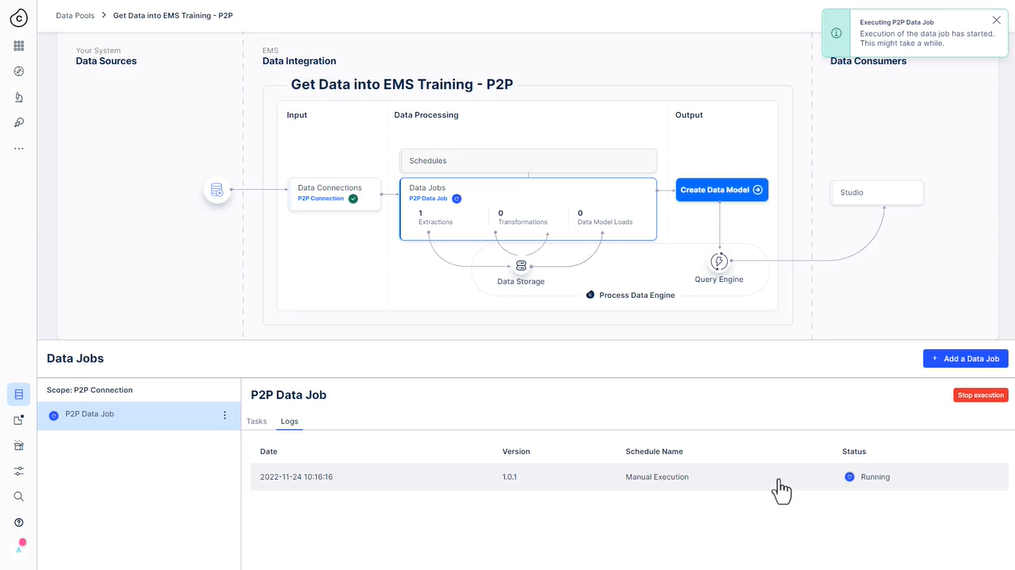
323 사용해 보세요 - 추출 설정
P2P 연결을 위한 추출을 설정할 때입니다. 준비 되었나요? 아직 연결되지 않은 경우 “ 시스템에 연결 “ 과정으로 이동하여 Process Connector 및 추출기 단원을 살펴보십시오.
평소와 같이 개인 훈련 환경 을 사용하여 이 운동을 완료하십시오. 이 과정의 리소스 섹션에서 액세스 방법에 대한 지침을 찾을 수 있습니다.
기본 지침으로 자신에게 도전하십시오. 작업을 확인하고 싶거나 도움이 필요한 경우 단계를 살펴보십시오.
기본 지침
- 데이터 풀 (EMS 교육으로 데이터 가져오기/또는 지정한 이름) 에서 P2P 연결을 기반으로 “P2P 데이터 작업”이라는 새 데이터 작업을 만듭니다.
- “P2P 원시 데이터”라는 새 추출을 만듭니다.
- 연결에 사용할 수 있는 모든 테이블 추가
-
각 테이블에 다음 필터를 추가합니다.
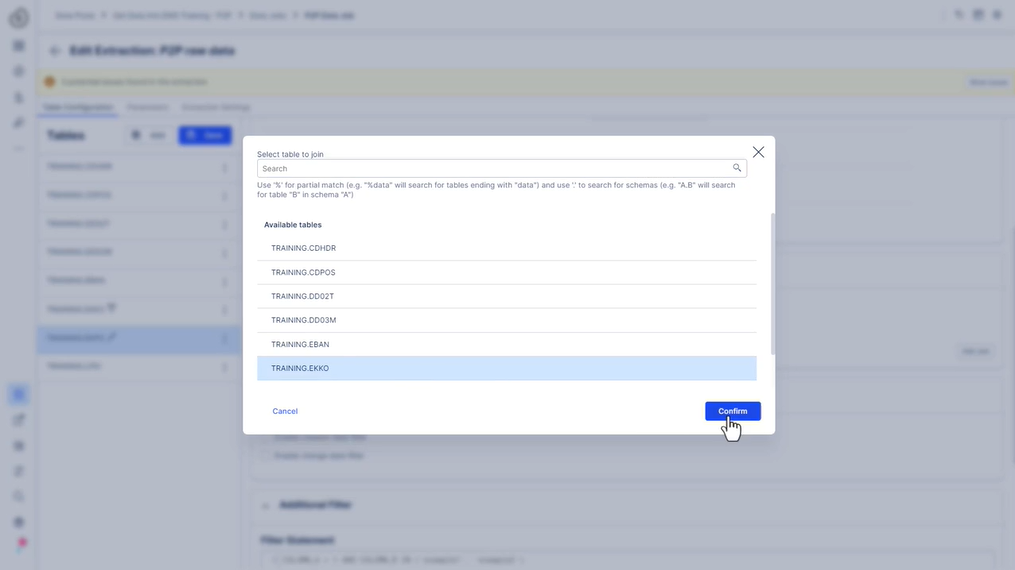
에코 시간 필터 -> 생성 날짜 필터: AEDAT >= 2014년 6월 1일 00:00 / 오전 12시 엑포 조인 구성: 조인 테이블 EKKO 사용자 정의 조인 조건: EKPO.MANDT = EKKO.MANDT AND EKPO.EBELN = EKKO.EBELN 조인된 테이블에 대한 필터: EKKO.AEDAT >= ‘01.06.2014’ 에반 시간 필터 -> 생성 날짜 필터: BADAT >= 2014년 4월 1일 00:00 / 오전 12시 CDHDR 시간 필터 -> 생성 날짜 필터: UDATE >= 2014년 6월 1일 00:00 / 오전 12시 CDPOS 조인 구성: 조인 테이블 CDHDR 사용자 정의 조인 조건: CDPOS.MANDANT = CDHDR.MANDANT AND CDPOS.OBJECTCLAS = CDHDR.OBJECTCLAS AND CDPOS.OBJECTID = CDHDR.OBJECTID AND CDPOS.CHANGENR = CDHDR.CHANGENR 조인된 테이블에 대한 필터: CDHDR.UDATE > = ‘01.06.2014’ 다른 테이블 테이블 LFA1, DD02T, DD03M의 경우 추가 필터링이 필요하지 않습니다. - 추출 저장 및 실행
단계
-
데이터 풀에서 “P2P 데이터 작업”이라는 새 데이터 작업을 생성하고 P2P 데이터 연결을 선택합니다.


-
데이터 작업에서 “테이블 추가”를 클릭하여 “P2P 원시 데이터”라는 새 추출을 만듭니다(시간이 촉박하지 않으면 템플릿을 사용하지 마십시오!).


- 연결에 사용할 수 있는 모든 테이블 추가



-
각 테이블에 다음 필터를 추가합니다.
a. EKKO
시간 필터 -> 생성 날짜 필터:
AEDAT >= 2014년 6월 1일 00:00(오전 12시
) 올바른 날짜를 선택하는 한)

b. EKPO
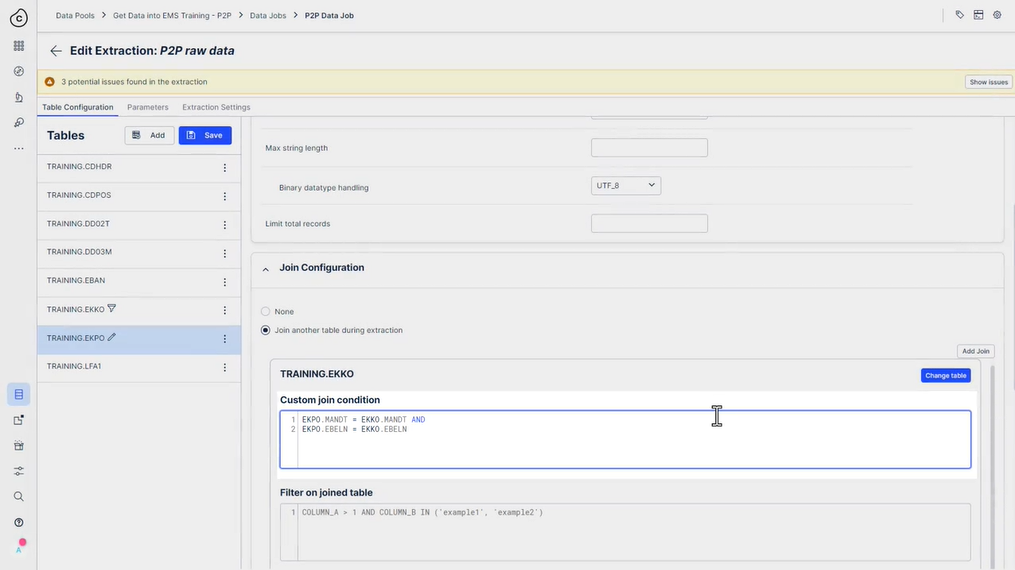
조인 구성:
Join table EKKO
사용자 정의 조인 조건:
EKPO.MANDT = EKKO.MANDT AND
EKPO.EBELN = EKKO.EBELN
조인된 테이블에 대한 필터:
EKKO.AEDAT >= ‘01.06.2014’
(Psssst: 날짜를 입력해야 합니다. 여기에는 날짜 선택기가 없기 때문에 정확히 표시된 대로 표시됩니다.)



c. EBAN
시간 필터 -> 생성 날짜 필터:
BADAT >= April 1st 2014, 12 AM

d. CDHDR
시간 필터 -> 생성 날짜 필터:
UDATE >= 2014년 6월 1일 오전 12시

e. CDPOS
조인 구성:
조인 테이블 CDHDR
사용자 정의 조인 조건:
CDPOS.MANDANT = CDHDR.MANDANT AND
CDPOS.OBJECTCLAS = CDHDR.OBJECTCLAS AND
CDPOS.OBJECTID = CDHDR.OBJECTID AND
CDPOS.CHANGENR = CDHDR.CHANGENR
조인된 테이블에 대한 필터:
CDHDR.UDATE >= ‘01.06.2014’

f. 테이블 LFA1, DD02T, DD03M의 경우 추가 필터링이 필요하지 않습니다.
-
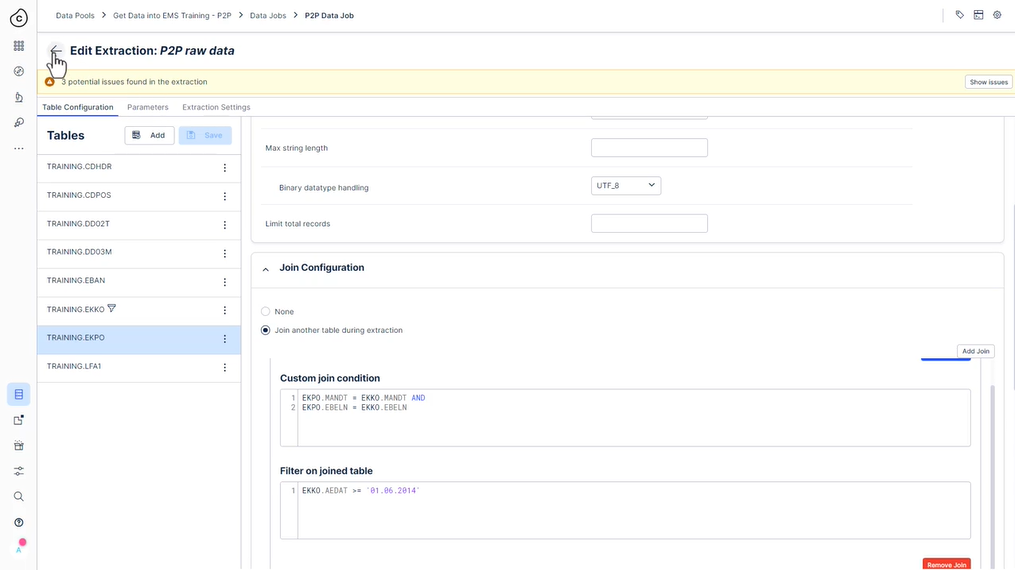
추출을 실행하고 “전체 로드”를 선택했는지 확인합니다(델타 필터가 없음을 나타내는 “잠재적 문제 발견..” 경고는 무시할 수 있습니다.:



-
참고: 현재 추출 실패로 이어질 수 있는 성능 문제가 발생했습니다. 이러한 문제를 해결하는 방법을 보려면 “결과 및 문제 해결”을 확인하십시오.
결과 및 문제 해결
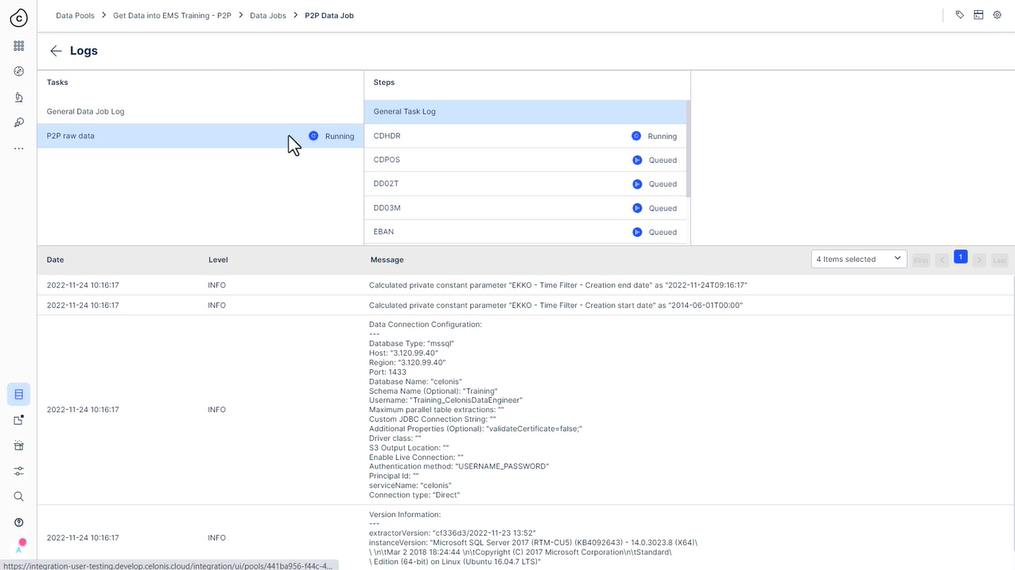
추출 실패?
교육 서버의 높은 부하로 인해 추출이 부분적으로 실패할 수 있습니다. 현재 이 문제를 해결하기 위해 노력하고 있습니다. 이 문제를 해결하려면 실패한 테이블만 추출해 보십시오.
-
로그를 확인하고 실패한 테이블을 확인하십시오. 단순히 다른 추출을 실행하고 실패한 테이블만 선택할 수 있습니다.

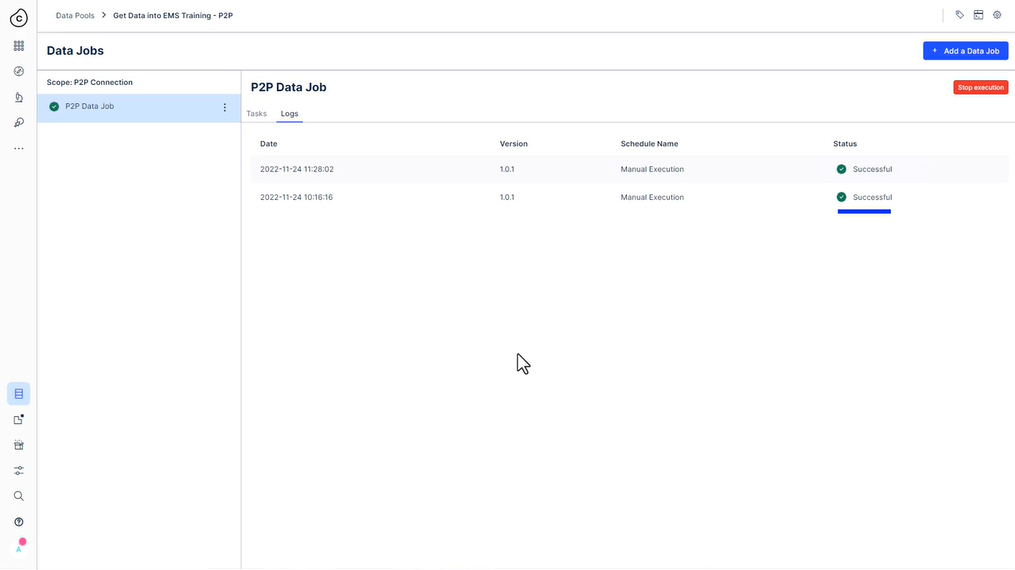
성공적인!
모든 것이 잘 되었다면 추출 작업이 성공적으로 실행되었고 테이블당 다음 수의 레코드를 추출했습니다.
| CDHDR | 17,002 |
| CDPOS | 34,648 |
| DD02T | 18 |
| DD03M | 1,474 |
| 에반 | 137 |
| 에코 | 14,067 |
| 엑포 | 28,360 |
| LFA1 | 2,058 |
추출된 레코드를 확인할 수 있는 두 가지 간단한 방법이 있습니다.
-
로그를 확인합니다.


-
변환 작업에서 SELECT COUNT(*) FROM {Table_Name}을(를) 실행합니다.
숫자가 정확하지 않습니까?
숫자가 꺼져 있으면 돌아가서 특정 테이블에서 추출을 확인하십시오.
오류로 막히셨나요? 문제가 추출 필터에 스며들었을 수 있습니다. 추출을 삭제하고 “P2P 원시 데이터” 템플릿을 사용하여 새 추출을 생성하고 실행할 수 있습니다.

324 가명화에 대하여
의미
추출 구성에서 열을 가명화하도록 선택하면 소스 시스템에 표시된 열 값이 해시된 값 으로 대체됩니다 .
익명화와 달리 가명화는 소스 시스템에 표시된 것과 동일한 값을 동일한 해시 값으로 대체하므로 분석에서 가명화된 값을 일관되게 활용할 수 있습니다. 즉, 데이터 패턴은 동일하게 유지됩니다.
즉, 원래 값을 재구성하는 것은 불가능합니다.
어디에서 발생합니까?
가명처리는 데이터 추출 중에 발생합니다. Celonis는 소스 시스템 데이터를 요청한 다음 수신 시 해당 데이터를 가명화하고 결국 EMS에 제공하기 전에 쪽모이 세공 형식으로 변환합니다.
어떻게 작동합니까?
사용자는 데이터 연결 » 고급 설정 에서 해싱에 SHA-1 또는 SHA-512(고정 솔트 사용)를 사용하도록 유연하게 구성할 수 있습니다.
33 매개변수
331 매개변수 사용
이제 추출 필터의 기본 사항을 이해하셨기를 바랍니다. 그러나 여러 테이블 또는 다른 추출 간에 값을 반복해서 필터링하려는 경우에는 어떻게 됩니까?
매번 수동으로 입력할 수 있지만 업데이트가 필요한 경우에는 어떻게 해야 합니까? 한 곳에서 값을 업데이트하는 것을 잊어버리면 추출에 심각한 영향을 미치 거나 데이터 로드를 중지할 수도 있습니다. 작업 속도를 높이고 반복되는 값의 업데이트를 놓칠 위험을 방지하기 위해 일반적으로 매개변수를 사용합니다.
작업 대 데이터 풀 매개변수
매개변수에는 “태스크 매개변수“와 “데이터 풀 매개변수“의 두 가지 수준이 있습니다. 상상할 수 있듯이 특정 작업 내에서만 작업 매개변수를 사용할 수 있는 반면 데이터 풀 매개변수는 전역 범위를 가지며 전체 데이터 풀에서 사용할 수 있습니다.
데이터 작업 태스크(추출 또는 변환) 내의 매개변수 탭에서 태스크 매개변수를 생성할 수 있습니다.

데이터 풀 매개변수를 생성하려면 데이터 풀 오른쪽 상단의 톱니바퀴 아이콘으로 이동하여 데이터 풀 매개변수를 선택합니다.


332 새 매개변수 생성: 파트 1
몇 가지 예를 살펴보겠습니다. 여러 테이블에서 특정 생성 날짜를 필터링한다고 가정해 보겠습니다. 매번 수동으로 이 작업을 수행하는 대신 “StartDate” 매개변수를 생성할 수 있습니다.
( 참고: 개인 환경에서는 이 단계를 수행할 필요가 없습니다.)
매개변수를 생성하려면 데이터 작업 -> 추출 작업(예: P2P 원시 데이터) -> 매개변수 탭 -> 새 매개변수로 이동합니다.


자리 표시자 이름은 매개변수를 참조하는 방법입니다. 태스크의 매개변수 중에서 고유해야 하며 공백이나 특수 문자를 포함할 수 없습니다.
“pretty” 이름과 매개변수가 무엇인지에 대한 간단한 설명을 정의할 수도 있습니다.
다음으로 매개변수 유형을 선택합니다. 비공개, 공개 및 동적의 세 가지 유형이 있습니다.
개인 매개변수는 데이터 풀 관리자만 보고 편집할 수 있는 반면 공용 매개변수는 작업에 액세스할 수 있는 모든 사람이 볼 수 있습니다. 둘 다 정적이므로 새 값을 입력할 때까지 해당 값이 변경되지 않습니다.
"동적" 매개변수는 기존 데이터에서 동적으로 생성되며 관리자만 볼 수 있습니다. 이 유형의 매개변수를 선택하면 테이블과 열이라는 두 개의 추가 필드를 작성해야 합니다. 그런 다음 매개 변수는 지정된 열에 대해 정의한 값 논리로 동적으로 설정됩니다. 이 논리는 다음과 같을 수 있습니다.
- 최대값,
- 최소값,
- 또는 목록의 일부가 됩니다.
동적 매개변수는 이 교육의 후반부에서 볼 수 있듯이 델타 하중을 정의하는 데 큰 도움이 됩니다.
동적 매개변수 옵션:

필요한 경우 추출이 아직 실행되지 않았고 가져올 데이터가 없는 경우 기본값을 설정할 수 있습니다.

333 새 매개변수 생성: 파트 2
예를 들어 매개 변수를 공개로 정의하고 데이터 유형 “날짜”를 선택한 다음 값 필드에 관련 날짜를 추가해 보겠습니다. 여기에서 데이터 풀 매개변수의 값을 재사용하거나 이 작업을 위한 값을 가질 수 있습니다.

저장 후 이제 테이블 구성으로 돌아가 방금 정의된 매개변수를 사용하여 “EKKO” 테이블의 하드 코딩된 날짜를 교환할 수 있습니다. 참고로 매개변수를 참조하기 위한 구문은 Celonis Analysis 내부의 변수와 매우 동일합니다.
추가 필터에서 EKKO의 날짜 매개변수 사용:

시작 날짜는 “EKPO”, “CDHDR” 및 “CDPOS” 테이블의 필터 문에서도 사용되므로 여기에 매개 변수를 삽입할 수도 있습니다.
조인 필터에서 EKPO의 날짜 매개변수 사용:

데이터 풀 매개변수 사용
동일한 값을 사용하는 다른 데이터 작업이 있는 경우 데이터 풀 매개변수를 고려하십시오. 태스크 매개변수와 달리 전체 데이터 풀에서 데이터 풀 매개변수를 사용할 수 있습니다.
작업 내에서 데이터 풀 매개변수를 참조하려면 먼저 로컬 작업 매개변수를 정의하고 위에서 강조 표시된 해당 데이터 풀 매개변수에 연결해야 합니다.
그렇지 않으면 데이터 풀 매개변수는 작업 매개변수와 정확히 동일한 방식으로 작동하며 동일한 유형(개인, 공용 및 동적)을 가집니다.
34 델타 추출
341 델타 추출 개요
델타 로드의 기능
추출을 설정할 때 “Delta Filter” 및 “Delta Load” 옵션을 본 것을 기억하십니까? 여기에서 Delta Loads에 대해 자세히 설명하겠습니다.
일반적으로 델타 로드를 수행할 때 새로운 데이터와 업데이트된 테이블 행이라는 두 가지 데이터 유형이 중요합니다 . 즉, 변경된 모든 것

중앙 구매 테이블 “EKPO”에 대한 생각:
새 테이블 행은 마지막 추출 작업 후에 생성된새 구매 주문 항목을 참조합니다.업데이트된 테이블 행은 이미 추출했지만 마지막 추출 이후업데이트된 구매 주문 항목을 나타냅니다. 예를 들어 공급업체와의 잘못된 통신으로 인해 구매 주문 항목의 가격이나 수량이 업데이트되었을 수 있습니다. UI에서 델타 필터는 어디에 구성되어 있습니까?
추출 작업의 사용자 인터페이스에서 날짜 변경 시간 필터 또는 추가 필터 아래의 델타 필터를 사용하여 델타 필터를 설정합니다 .
UI 옵션 1 - 날짜 필터 변경:

UI 옵션 2 - 델타 필터 문

다음으로 델타 로드를 구성하는 세 가지 주요 방법을 살펴보겠습니다.
- 날짜 변경
- 연속 숫자
- 만든 날짜(흔하지 않음)
342 변경 날짜 사용
“델타 로드”를 구성하려면 소스 시스템의 테이블을 아는 것이 중요합니다. 보다 정확하게는 “델타 로드”를 설정하는 데 사용할 수 있는 열을 알아야 합니다. 그러나 열을 자세히 살펴보기 전에 사용자 인터페이스를 간단히 살펴보겠습니다.
델타 로드를 구현하는 첫 번째이자 가장 쉬운 방법은 추출하려는 테이블에 “ 변경 날짜" 열이 포함되어 있는 경우입니다. 대부분의 테이블에는 테이블 행이 새로 생성되거나 변경될 때마다 현재 시간으로 업데이트되는 열이 있습니다. EKPO 테이블은 이에 대한 완벽한 예입니다. EKPO에는 “날짜 변경 열”인 AEDAT라는 열이 포함되어 있습니다.
AEDAT 열과 혼동하지 마십시오! EKKO 테이블에도 AEDAT라는 열이 있지만 EKKO의 경우 AEDAT는 실제로 만든 날짜 입니다 .
따라서 EKPO의 경우 “변경 날짜”가 있는 모든 행을 추출하고 이미 로드된 최신 변경 날짜와 비교하기만 하면 됩니다.
변경 날짜 필터를 사용하는 경우 필터에서 열을 선택하기만 하면 추출에서 이를 사용합니다. 델타 로드를 실행할 때:

대안은 동적 매개변수를 사용하고 델타 필터에 추가하는 것입니다.


업데이트된 행의 경우 Celonis는 기본 키를 기반으로 중복 항목을 자동으로 식별 하고 새 행을 삽입하여 해당되는 경우 이전 기존 행을 덮어씁니다.
대부분의 소스 시스템에서 Celonis는 테이블의 기본 키를 자동으로 식별합니다. 그렇지 않은 경우 각 추출 작업에서 모든 테이블의 기본 키를 수동으로 정의할 수 있습니다 .
343 연속 숫자 사용
“델타 로드”를 구현하는 두 번째 방법은 연속 번호를 사용하는 것입니다 . 이 방법의 좋은 예는 SAP 시스템의 모든 변경 사항을 저장하는 “CDPOS” 테이블입니다. CDPOS에서 행은 업데이트되지 않지만 변경이 발생할 때마다 테이블에 새 행이 생성됩니다 . 모든 행에는 “변경 번호"(CHANGENR)라는 연속 번호가 있습니다. 이 번호를 사용하면 마지막 로드의 최대 변경 번호보다 높은 변경 번호가 있는 행만 추출합니다.

이를 설정하기 위해 가장 높은 로드된 변경 번호를 확인하고 이를 소스 시스템 변경 번호와 비교하는 동적 매개변수를 생성할 수 있습니다.
동적 매개변수 설정:

매개변수로 델타 필터 설정:

344 생성 날짜 사용
테이블에 “변경 날짜” 또는 “변경 번호”가 포함되어 있지 않은 경우 델타 로드를 구현하는 데 사용할 수 있는 덜 일반적인 옵션이 하나 더 있습니다. 테이블의 “생성 날짜"를 사용할 수 있습니다 . 변경 날짜 시간 필터에서 설정할 수 있습니다.

델타 로드로 추출하려는 두 가지 유형의 데이터( 신규 및 업데이트된 테이블 행) 를 생각하면 “생성 날짜"를 사용하여 새 행을 쉽게 추출할 수 있습니다.
반대로 업데이트된 행은 “만든 날짜"를 사용하여 추출할 수 없습니다.
“EKKO”가 좋은 예입니다. “EKKO”에는 구매 주문서의 생성 날짜인 타임스탬프 “AEDAT”가 포함되지만 “변경 날짜”는 포함되지 않습니다.
그러나 생성 날짜를 사용하여 업데이트된 테이블 행을 어떻게 추출할 수 있습니까?
오프셋의 필요성
그러기 위해서는 “ offset “이 있는 데이터를 추출해야 합니다. 즉, 이미 추출한 마지막 구매 주문서 이후에 생성된 모든 데이터를 추출하는 대신 3개월 전에 생성된 모든 구매 주문서도 추출해야 합니다. 3개월은 예시일 뿐이며 이 경우 오프셋을 나타냅니다.
물론 이런 방식으로 데이터를 추출하면 많은 중복 행이 생성됩니다. EMS가 이를 처리하고 기본 키를 사용하여 기존 테이블의 모든 중복 항목을 자동으로 삭제한다는 점을 명심하십시오 .
오프셋은 전적으로 비즈니스 및 특정 요구 사항에 따라 다릅니다. 다른 기업에서는 최대 반년의 오프셋이 필요한 반면 일주일만 오프셋으로 사용하는 것이 이치에 맞는 경우도 있습니다. 일반적으로 대부분의 업데이트가 데이터 추출에 포함되도록 오프셋을 설정하려고 합니다. 일반적으로 잠재적으로 누락된 업데이트를 캡처하기 위해 대부분 주말에 더 큰 시간 간격으로 실행되는 전체 로드가 추가로 설정됩니다.
오프셋 설정 “EKKO” 테이블의 경우 3개월의 오프셋이 모든 업데이트의 99%를 가져오는 것으로 가정합니다. 드롭다운을 사용하여 생성 날짜를 선택하고 오프셋을 3개월로 지정할 수 있습니다.

345 델타 추출 요약
요약하면 전체 및 델타 로드 구성의 대부분은 추출 자체 내에서 수행됩니다. 델타 로드를 설정하려면 다음을 사용할 수 있습니다.
- 날짜 변경,
- 연속 변경 번호 또는
- 특정 오프셋이 있는 생성 날짜 .
각 접근 방식에 대한 개요는 다음과 같습니다.

전체 로드와 델타 로드의 차이점은 “델타 필터”와 “변경 날짜 시간 필터 활성화”의 두 필터가 고려된다는 점에 유의하십시오.

35 메타데이터 변경
소스 데이터의 구조가 변경되면 어떻게 될까요?
데이터 작업 내에서 델타 추출 작업이 실패하는 일반적인 이유는 소스 시스템 메타데이터, 특히 소스 시스템 테이블에서 열이 추가되거나 제거되었기 때문입니다.
메타데이터 변경 후 델타 로드 실패를 방지하기 위해 추출에서 “메타데이터 변경 포함"을 활성화할 수 있습니다. 그러면 델타 추출이 추가되거나 제거된 열에 맞게 자동으로 조정되고 로그에 간단한 경고가 전송됩니다. 그런 다음 새 메타데이터를 다운스트림 활동에 사용할 수 있습니다.

추출에 테이블의 모든 열이 포함되지 않는 경우 옵션을 선택하더라도 메타데이터 추가가 추출되지 않는다는 점에 유의하십시오.
언제 이 옵션을 활성화해야 합니까?
여기서 고려해야 할 세 가지 사항이 있습니다.
- NULL 값: 메타데이터 변경 사항을 포함하는 옵션을 활성화하면
데이터에 NULL 값이 생성될 수 있습니다. 테이블 EKPO에 새 열을 추가한다고 상상해 봅시다. 이 열은 각 구매 주문 항목에 대한 정보를 제공하며, 특히 항목이 내부적으로 사용되는지 또는 최종 제품에 사용되는지 여부를 나타냅니다. 그러나 이 정보는 새 열이 추가된 후에만 채워지며 과거 구매에 대해서는 다시 채워지지 않습니다. 이로 인해 소스 시스템에 불일치가 발생할 수 있으며 Celonis 내에서 추출된 데이터에 반영됩니다. - 데이터 유형 변경이 처리되지 않음: 또한
데이터 유형에 대한 메타데이터 변경이 있는 경우 기능이 업데이트를 처리하지 않습니다. 예를 들어 열의 데이터 유형이 정수에서 문자열로 변경되면 테이블이 올바르게 로드되지 않습니다. 이 경우 충돌을 제거하려면 전체 로드가 필요합니다. - 델타 로드가 더 빠름: 지속적으로 증가하고 확장되는 테이블을 추출하는 경우 이 기능을 활성화하면 델타 로드가 계속 실행됩니다. 결국 델타 로드는 로드 시간을 줄이고 전체 로드보다 빠릅니다.
36 문제 해결
추출 오류 처리
추출을 실행할 때 오류가 발생하여 실패하면 네 가지 수준의 정보가 모두 활성화된 로그를 확인하십시오.
로그 탭으로 이동하여 실행을 선택합니다.

로그에서 네 가지 수준의 로그를 모두 활성화하고 확인하려는 작업 및 단계(테이블)로 드릴다운해야 합니다.

일반적인 오류
몇 가지 일반적인 실수는 다음과 같습니다.
필터 의 구문 오류잘못된 필터상자 의 쿼리- 잘못된
조인 문
시간 필터
한 가지 명심해야 할 점은 UI 기반 시간 필터입니다. 표시되는 날짜의 형식은 브라우저와 해당 언어에 따라 다릅니다. 원하는 날짜를 입력할 때 이 점에 주의하세요.
물론 조인된 테이블이나 추가 필터 섹션에 시간 필터를 추가하면 달력 위젯이 없기 때문에 형식은 표준 Vertica 구문입니다. 예를 들면 다음과 같습니다.

추출 미리보기
조인 또는 기타 필터를 테스트할 때 추출 미리 보기를 사용하고 보기를 전체 화면으로 확대하여 로그를 확인하십시오. 이렇게 하면 나중에 추출 실패 후 다시 돌아올 필요가 없습니다.


디버그 모드
기본 로그에 운이 없다면 “디버그 모드"를 활성화할 수 있습니다. 이렇게 하면 로그에 디버그 정보가 채워지고 3일 동안 유지됩니다.

도움말 사용
문제에 대한 도움말 문서에서 검색을 실행하십시오. 반복되는 많은 문제가 문서화되어 있으며 문제를 직접 해결할 수 있습니다.
연락처 지원
위 사항을 모두 확인한 후에도 문제가 해결되지 않으면 servicedesk@celonis.com 으로 연락하여 전체 URL을 공유하십시오. 기본적으로 URL에는 인스턴스, 데이터 풀, 데이터 작업 및 작업을 가리키는 모든 ID가 포함됩니다.

37 성능 기본 사항
371 보다 성능이 뛰어난 추출의 기본 사항
데이터 통합에서 작업할 때마다 성능 추출을 설정하는 것이 최우선 순위입니다. 올바르게 설정하면 로딩 시간이 단축되고 소스 시스템의 부하가 줄어들며 다운스트림 활동의 지연이 줄어듭니다.
추출의 경우 다음 모범 사례를 따라야 합니다.
관련 없는 열 선택 취소- 필터를 적용하여
필요한 데이터만 추출 - 소스 시스템의 용량에 따라 시스템 연결에서 “
최대 병렬 추출 수"를 조정하십시오 . 데이터 연결을 만들 때 고급 설정에서 다음을 찾을 수 있습니다.

38 데이터 작업 추출 요약
382 데이터 작업 추출 요약
Data Jobs 추출 구성을 요약하면 다음을 배웠습니다.
테이블 열을 구성하는 방법. 옵션에는 열 선택 제한, 데이터 유형 변경, 데이터 가명화 및 기본 키 할당이 포함됩니다.- 데이터 볼륨을 줄이기 위해
필터를 추가하는 방법. 한 가지 중요한 필터 유형은 시간 필터입니다. - 추출에서
테이블을 조인하고 이러한 조인된 테이블에 필터를 적용하는 방법. 매개 변수를 사용하여 작업 속도를 높이고 하나 이상의 작업에서 동일한 값을 사용할 때 실수를 방지하는 방법 .- 변경 날짜, 연속 번호 또는 오프셋이 있는 생성 날짜를 사용하여
델타 로드를 설정하는 방법 - 데이터 구조가 변경될 때 델타 추출을 계속 실행하기 위해 메타데이터 변경
옵션을 사용하는 방법과 시기 - 로그로 추출 문제를 해결하고 기
본 성능 검사를 적용하는 방법.
이 첫 번째 섹션은 데이터 작업 추출 에 관한 것이었습니다 .

4 복제 조종석 - 데이터 추출
41 Replication Cockpit을 사용해야 하는 경우
411 복제 조종석 개요
소스 시스템에서 데이터를 추출하는 또 다른 방법은 Replication Cockpit을 사용하는 것입니다. Replication Cockpit은 실시간으로 소스 시스템에서 EMS로 데이터를 복제 할 수 있는 데이터 파이프라인 오케스트레이션 도구입니다 . 기존 데이터 작업을 보완할 수 있으며 Celonis 운영 앱을 사용하는 경우와 같은 실시간 연결 사용 사례 에 맞게 특별히 조정되었습니다.
주요 이점 중 일부는 다음과 같습니다.
실시간 연결: 추출은 사용자 정의 일정 없이 자동으로 조정됩니다 .자동 자체 복구: 일시적인 오류가 발생할 경우 추출을 수정하고 다시 실행합니다.속도 및 안정성: 추출이 변환과 분리되어 있기 때문에 추출이 더 빠르게 실행되고 오류가 덜 발생합니다.
데이터 통합 UI의 이 다이어그램은 Replication Cockpit이 있는 종단 간 데이터 파이프라인을 보여줍니다.

Replication Cockpit은 실시간 델타와 전체 추출 및 변환을 적절하게 처리합니다. 나머지는 데이터 작업이 지원합니다. 변환은 “데이터 변환” 과정에서 다룹니다.
추출을 확대해 보겠습니다.
412 데이터 파이프라인 설계
RC( Replication Cockpit ) 및 DJ( Data Jobs )는 소스 시스템에서 데이터를 추출하여 Celonis EMS로 푸시하는 방법을 정의하고 조율하는 동일한 목적을 수행하는 두 가지 도구입니다. Replication Cockpit은 실시간 추출 사용 사례를 위해 설계되고 권장되는 반면 데이터 작업은 실시간 테이블 새로 고침이 아닌 예약이 필요한 분석 사용 사례를 위한 것입니다.
아래 매트릭스는 Replication Cockpit을 권장하는 테이블 유형(녹색)을 요약한 것입니다. 운영 사용 사례 (예: 앱) 의 경우 실시간 모드에서 트랜잭션 테이블을 추출하고 데이터 작업을 통해 매일 밤 또는 매주 메타데이터 테이블을 추출하는 것이 좋습니다.

참고: Replication Cockpit에는 더 이상 개념 델타 필터가 없습니다 . 실시간 추출을 위해 시스템을 준비하면(예: 소스 시스템에서 변경 로그 테이블 및 트리거 설정 ) 복제가 자동으로 델타를 캡처합니다.
413 트랜잭션 대 메타데이터 테이블
트랜잭션 테이블과 메타데이터 테이블의 차이점은 무엇입니까?
트랜잭션 테이블과 메타데이터 테이블을 구분하는 정확한 공식은 없지만 일반적인 접근 방식은 다음과 같습니다.
| 트랜잭션 | 테이블에 사례 또는 활동이 포함된 경우 트랜잭션이므로 실시간으로 추출해야 합니다. 예를 들면 EKKO, EKPO, CDPOS, CDHDR, BKPF 등이 있습니다. 트랜잭션 테이블은 일반적으로 매우 자주 변경됩니다 . |
| Metadata | 메타데이터 테이블에는 자주 업데이트되지 않거나 운영 관점에서 그다지 중요하지 않은 상대적으로 정적인 정보가 포함 됩니다 . |
| 이러한 테이블은 Replication Cockpit 또는 데이터 작업에서 추출할 수 있습니다. SAP 세계에서는 모든 T…. 및 D…. 테이블이 이 범주에 속하며 때로는 마스터 데이터 테이블(예: 해당 데이터가 중요하지 않은 경우 KNB1, LFA1, MARA 및 MARC)에 속합니다. 운영 사용 사례. |
궁극적으로 Replication Cockpit은 트랜잭션 및 필요한 경우 메타데이터 테이블을 포함하여 소스 시스템에서 지속적인 데이터 복제를 실행할 수 있습니다 .
42 추출 설정
421 Replication Cockpit에서 추출 설정
다음은 Replication Cockpit에서 추출을 설정하는 세 가지 기본 단계를 보여주는 짧은 비디오입니다.
- 테이블 추가
- 추출 구성
- 초기화(완전추출)
다음 페이지에서는 이 비디오에서 방금 본 내용을 검토하고 심화할 것입니다.
422 Replication Cockpit에 테이블 추가
Replication Cockpit에 대한 사용 사례(운영 사용 사례와 분석 사용 사례)가 명확해지면 다음 단계는 Replication Cockpit에 실시간 관련 테이블을 추가하는 것 입니다 .
이는 주로 표준 프로세스(예: P2P, O2C, AP 등)용 템플릿을 통해 이루어지지만 템플릿 범위를 벗어나는 사용자 정의 테이블에 대해서는 여전히 자체 결정을 내려야 합니다.
델타를 효과적으로 캡처하고 복제가 가능하도록 소스 시스템 측에서 선택한 테이블에 대한 트리거 및 변경 로그가 필요합니다 .
참고: SAP 컨텍스트에서 CDPOS 및 CDHDR은 이 규칙의 예외입니다. 이 두 테이블의 경우 SAP에서 트리거 및/또는 변경 로그 테이블이 필요하지 않습니다. 트리거 및 필터 정의 없이 이러한 테이블을 복제할 수 있습니다. Replication Cockpit은 CHANGENR 필드를 사용하여 Celonis EMS에서 이미 사용 가능한 최신 CHANGENR을 기반으로 델타를 자동으로 식별합니다.
테이블을 추가하는 방법
Replication Cockpit으로 처음 이동하면 실시간 모드(로그 변경)가 활성화된 모든 연결이 왼쪽에 표시됩니다. “범위”는 연결을 의미합니다.

실시간 모드에서 테이블을 복제하려면 각 Replication Cockpit 연결에 테이블을 추가해야 합니다. 이것은 내장된 프로세스 템플릿 s 를 통 하거나 테이블을 하나씩 추가 하여 수행할 수 있습니다 .
템플릿 사용

이 방법으로 템플릿을 추가하는 동안 Replication Cockpit에 모든 권장 테이블이 추가되지만 필요할 수 있는 데이터 풀 매개변수 및 보완 데이터 작업이 생성되지 않습니다. 따라서 완전한 패키지를 위해 Marketplace에서 Process Connectors를 사용하는 것이 좋습니다 .
수동으로 테이블 추가

연결(범위) 드롭다운에서 “추가”를 선택하여 테이블을 수동으로 추가할 수 있습니다.
추가된 테이블에 트리거/변경 로그가 없으면 이러한 개체가 소스 시스템에 존재하지 않는다는 경고가 표시됩니다.

423 복제 구성
Replication Cockpit에 테이블을 추가한 후 데이터 작업의 델타 추출에 해당하는 복제를 구성하고 전체 추출에 해당하는 초기화를 구성할 수 있습니다. 여기에 있는 옵션은 데이터 작업 추출에 있는 것과 부분적으로 유사합니다. 빠르게 둘러보세요. 암기할 필요가 없습니다!

일반적인

컬럼구성 - 컬럼 선택, 선택 해제, 가명화. EMS에서 대상 테이블 이름 재정의- 삭제 기록 -
삭제 기록을 추출할지 여부를 선택합니다. 또한 추출된 삭제된 레코드로 수행할 작업을 결정합니다. 여기서 선택은 원본 시스템의 동작과 삭제된 데이터를 EMS에 보관해야 하는지 여부에 따라 다릅니다. 변경 로그구성 - 예외적인 경우 테이블 대신 데이터베이스 보기를 복제할 수 있습니다 . 보기에는 트리거 또는 변경 로그 테이블이 없으므로 이 옵션을 사용하여 테이블과 연결된 다른 변경 로그를 가리킬 수 있습니다.
추출 매개변수

데이터 작업에 익숙하다면 매개변수는 새로운 것이 아닙니다. 한 가지 차이점은 여기에 있는 매개변수가 모두 데이터 풀 매개변수라는 것입니다.
필터 문

데이터 작업 추출 작업과 마찬가지로 복제 및 초기화 모두에 필터를 적용할 수 있습니다.
초기화 조인 구성

여기에서 초기화 에만 조인 구성을 적용할 수 있습니다 . 복제(델타 추출)에는 조인이 불가능하다는 점에 유의하십시오.
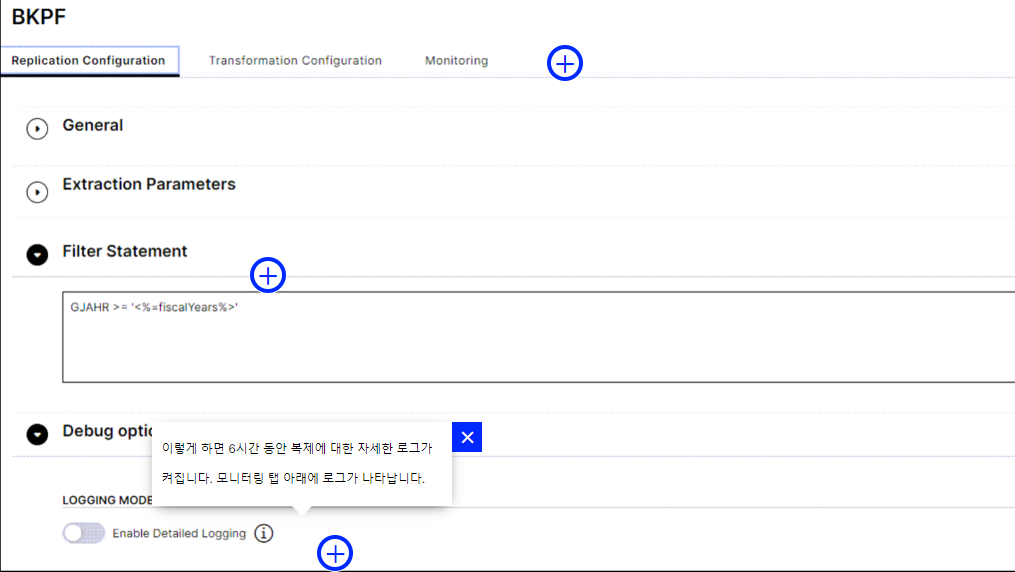
디버그 옵션

이 세부 로깅을 켜면 모니터링 탭에서 복제 및 초기화의 기본 상태와 로그를 찾을 수 있습니다.
실행을 선택하여 해당 로그(예: 시작 시간, 기간 및 추출된 레코드 수)를 표시합니다.

424 복제 구성 옵션 파트 1
테이블을 추가한 후 복제를 구성할 수 있습니다. 핫스팟을 클릭하여 각 옵션에 대해 자세히 알아보세요.
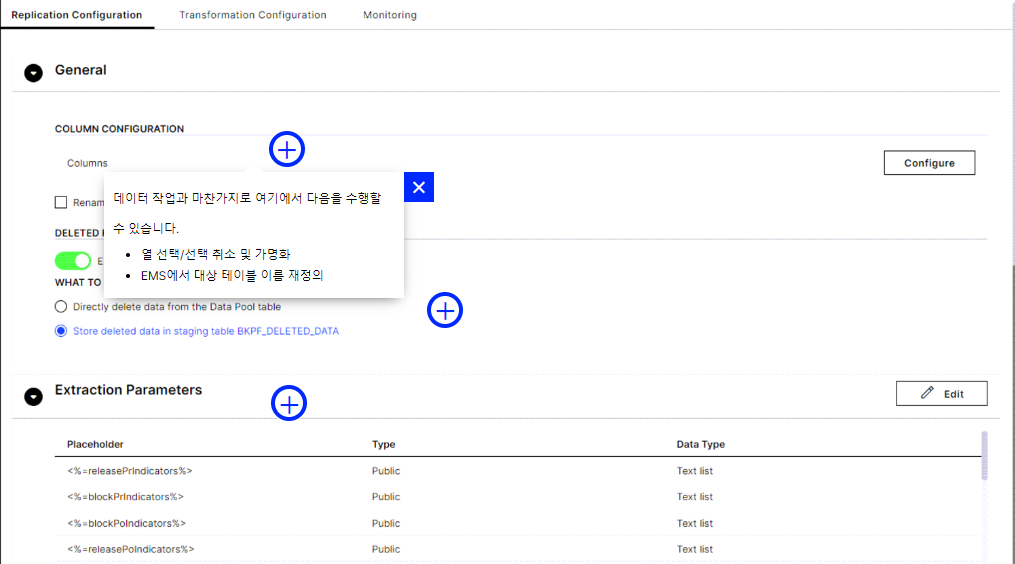
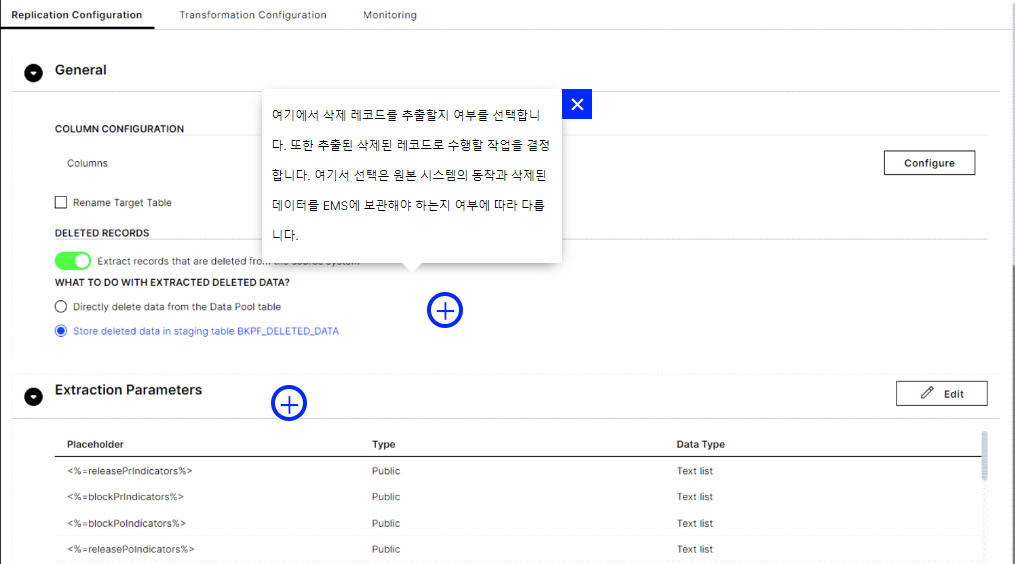
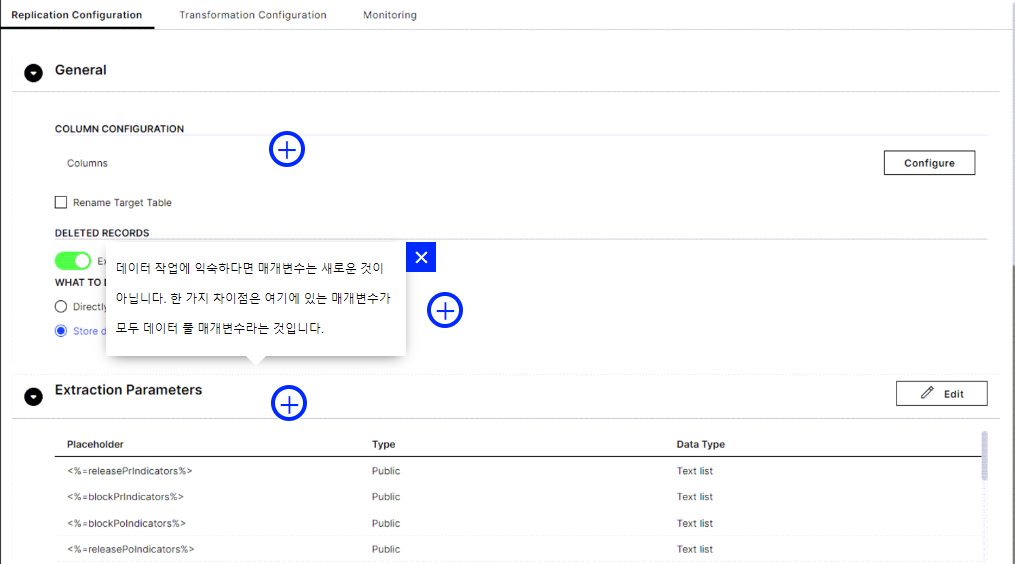
삭제된 레코드는 복잡한 소스 시스템 및 실시간 추출로 작업할 때 까다로운 주제가 될 수 있습니다. 자세한 내용은 이 도움말 문서 의 삭제 질문을 살펴보십시오 .
425 복제 구성 옵션 파트 2
고려해야 할 추가 구성 옵션은 다음과 같습니다.
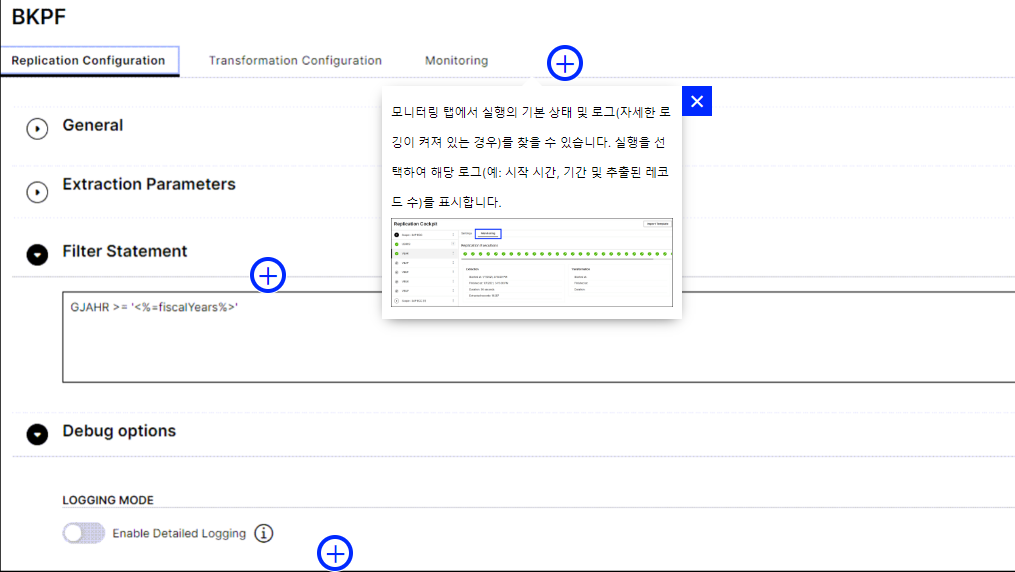
426 복제 초기화 및 시작
테이블 추가 및 구성을 마쳤으면 이제 복제를 시작할 차례입니다. 먼저 테이블을 "초기화"합니다. 이는 Replication Cockpit을 사용하여 완전히 로드한다는 의미입니다. 초기화는 데이터 작업 전체 로드와 동일하지만 한 가지 주요 차이점이 있습니다. 초기화는 Replication Cockpit에서 한 번만 실행됩니다 .

추출 초기화 후 실시간 델타 추출(복제)이 자동으로 시작되며 수동으로 다시 트리거하거나 데이터 작업을 사용하여 설정하지 않는 한 정기적으로 예약된 전체 테이블 추출이 더 이상 없습니다.
복제만 시작
초기화를 건너뛰거나 복제를 직접 시작해야 하는 경우 테이블의 점 3개 메뉴에서 “복제”를 클릭하기만 하면 됩니다. 데이터 연결 옆에 있는 점 3개 메뉴를 사용하고 “모두 복제”를 사용하여 이 작업을 대량으로 수행할 수도 있습니다.

427 장애 및 성능 저하 상태 감시
복제는 자동으로 실행되며 장애가 발생하더라도 다음 복제는 이전 복제에서 보류 중인 레코드를 추출하여 해결해야 합니다. 그러나 파이프라인에 시스템 문제가 있는 경우 복제가 계속 실패합니다. 기본 그래픽에서 “저하됨” 또는 “실패”로 필터링하여 문제가 있는 테이블을 빠르게 확인할 수 있습니다. Degraded는 단순히 특정 수의 실패 후 설정된 상태입니다.

이메일 알림 설정
테이블이 성능 저하 상태가 될 때마다 이메일을 받도록 경고를 설정할 수 있습니다 . 다음은 샘플 이메일입니다.

경고에 대한 횟수 및 시간 실패 임계값 설정
복제 성능이 저하되는 시점을 결정합니다. 수 임계값이 5이고 경고를 활성화한 경우 5번의 후속 복제 실패 후 테이블의 복제 상태가 "저하"되고 경고 이메일을 받게 됩니다. 또는 실행 시간 임계값을 설정한 후 테이블이 “저하됨”으로 설정될 수도 있습니다.


428 복제 일정 설정
달력은 복제가 실행되는 시간대를 정의합니다 . 이것은 주로 2가지 사용 사례를 제공합니다.
- 데이터 작업을 통해 실행되는 전체 로드와의 충돌을 방지하려면
- 특정 시간 동안 소스 시스템에 부하가 발생하지 않도록 하려면
캘린더는 연결 수준 설정 이며 지정된 연결 범위 내에서만 테이블 복제를 관리합니다.

Replication Cockpit 달력의 예:

43 과정 요약
432 과정 요약
이 과정은 시스템에 연결한 후 추출 구성에 관한 것입니다 . 데이터 작업 또는 Replication Cockpit을 사용하여 수행합니다.

Replication Cockpit으로 추출을 요약하면 다음과 같습니다.
Replication Cockpit을 사용해야 하는 경우- 즉, 운영 사용 사례 및 트랜잭션 테이블트랜잭션 대 메타데이터 테이블과 이 둘을 구별하는 방법- Replication Cockpit에서 테이블을 추가하고
복제를 초기화 및 시작하는 방법 - Replication Cockpit에서 구성할 수 있는
추출 옵션(복제 및 초기화):- 열 선택 및 가명화
- 삭제된 델타 레코드 처리
- 추출 필터(델타 필터 없음!)
- 초기화 조인
- 자세한 로깅
- 경고 및
실패 임계값을 설정하는 방법 복제 일정을 설정하는 방법
데이터 작업 추출에서 이전에 배운 내용이 확실하지 않습니까? 필요한 경우 마지막 섹션 요약은 다음과 같습니다.
데이터 작업 요약
테이블 열을 구성하는 방법. 옵션에는 열 선택 제한, 데이터 유형 변경, 데이터 가명화 및 기본 키 할당이 포함됩니다.- 데이터 볼륨을 줄이기 위해
필터를 추가하는 방법. 한 가지 중요한 필터 유형은 시간 필터입니다. - 추출에서
테이블을 조인하고 이러한 조인된 테이블에 필터를 적용하는 방법. 매개 변수를 사용하여 작업 속도를 높이고 하나 이상의 작업에서 동일한 값을 사용할 때 실수를 방지하는 방법 .- 변경 날짜, 연속 번호 또는 오프셋이 있는 생성 날짜를 사용하여
델타 로드를 설정하는 방법 - 데이터 구조가 변경될 때 델타 추출을 계속 실행하기 위해 메타데이터 변경
옵션을 사용하는 방법과 시기 - 로그로 추출 문제를 해결하고
기본 성능 검사를 적용하는 방법.